![[messl image]](messl.jpg)
Model-based Expectation Maximization Source Separation and
Localization (MESSL)
Michael I Mandel and Daniel P W Ellis
Abstract
We describe a system, referred to as MESSL, for separating and
localizing multiple sound sources from an underdetermined reverberant
two-channel recording. By characterizing the interaural spectrogram
for single source recordings, we construct a probabilistic model of
interaural parameters that can be evaluated at individual spectrogram
points. Multiple models can then be combined into a mixture model of
sources and delays, which reduces the multi-source localization
problem to a collection of single source problems. We derive an
expectation maximization algorithm for finding the maximum-likelihood
parameters of this mixture model, and show that these parameters
correspond well with interaural parameters measured in isolation. As
a byproduct of fitting this model, the algorithm creates probabilistic
spectrogram masks that can be used for source separation. In
experiments performed in simulated anechoic and reverberant
environments, MESSL on average produced a signal-to-distortion ratio
1.6 dB greater than four comparable algorithms.
Example: Two speakers in reverb
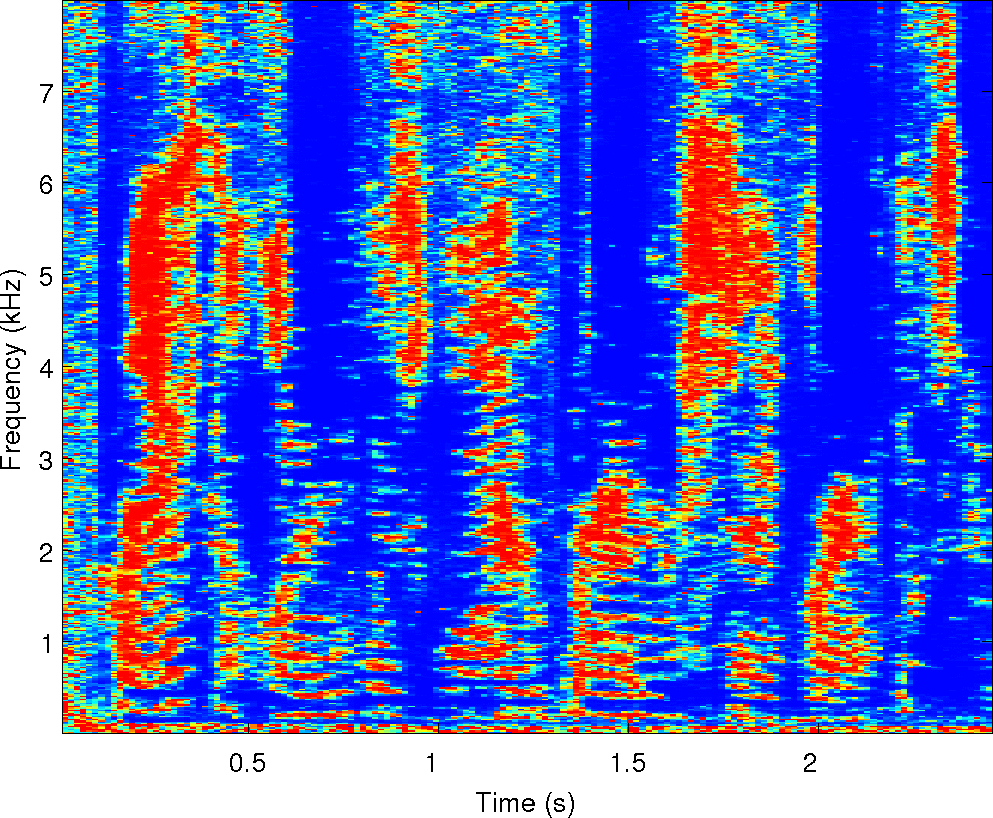
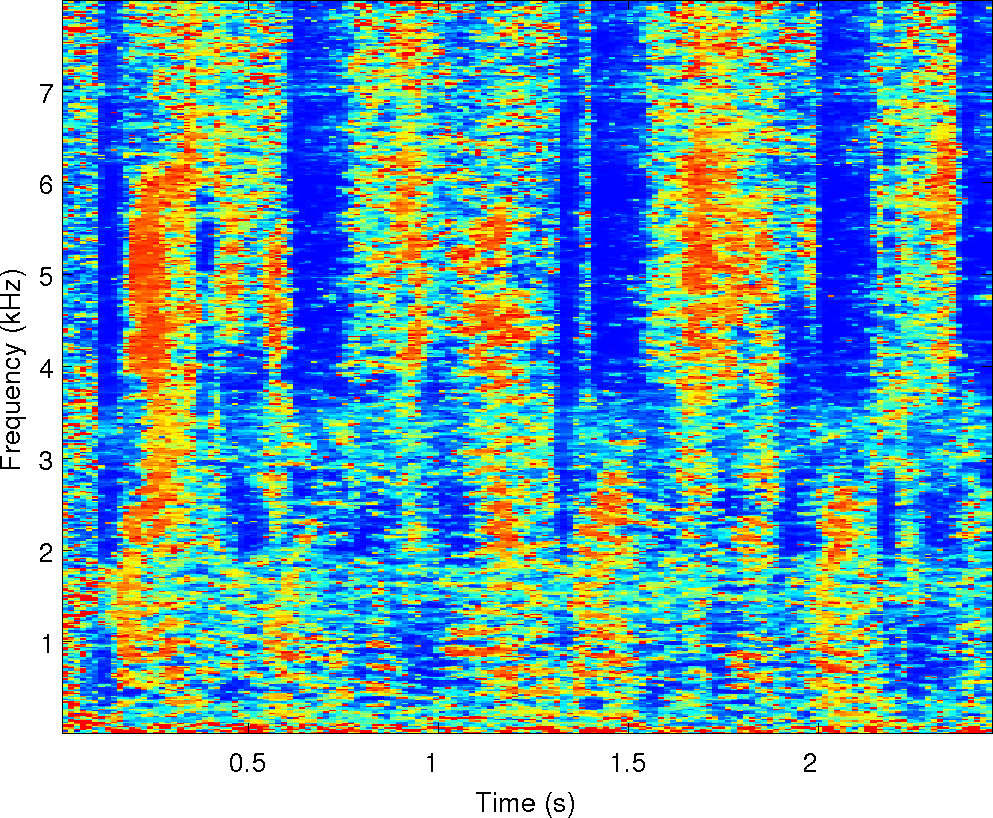
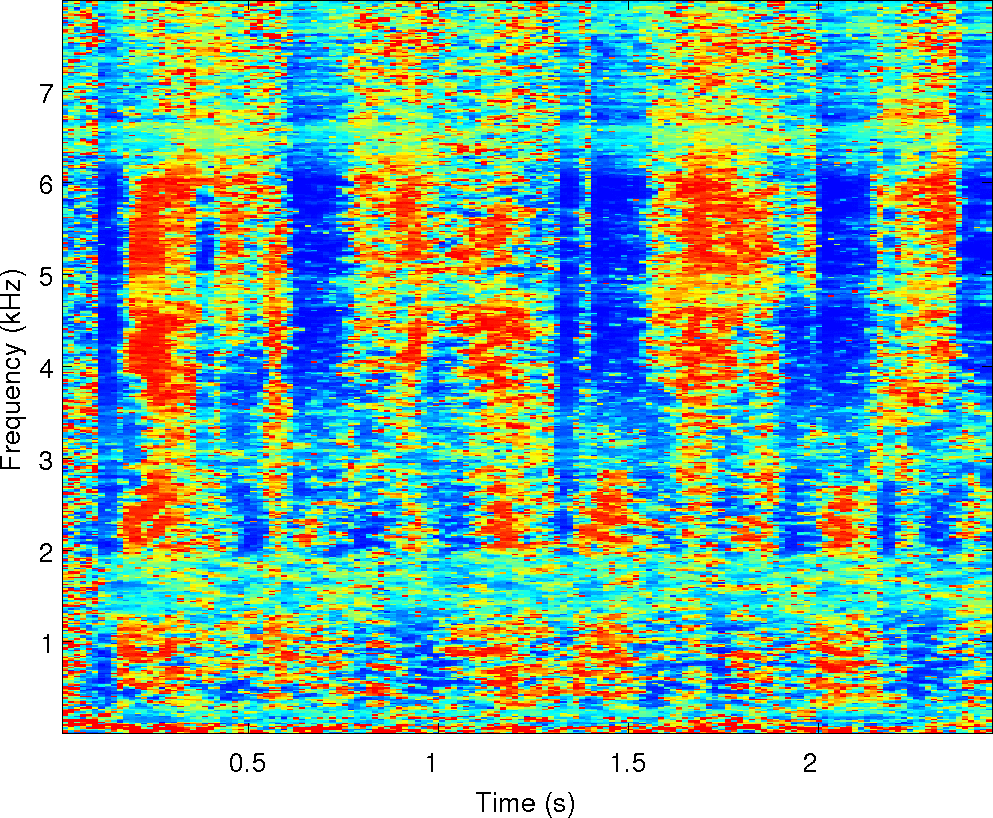
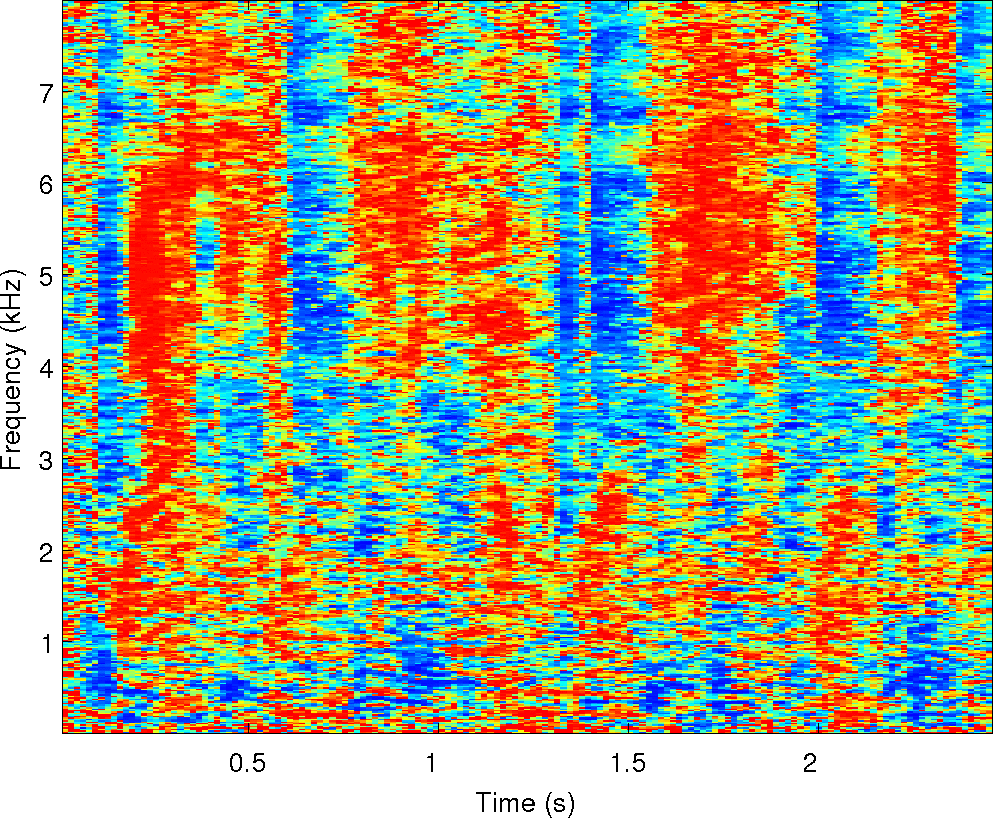
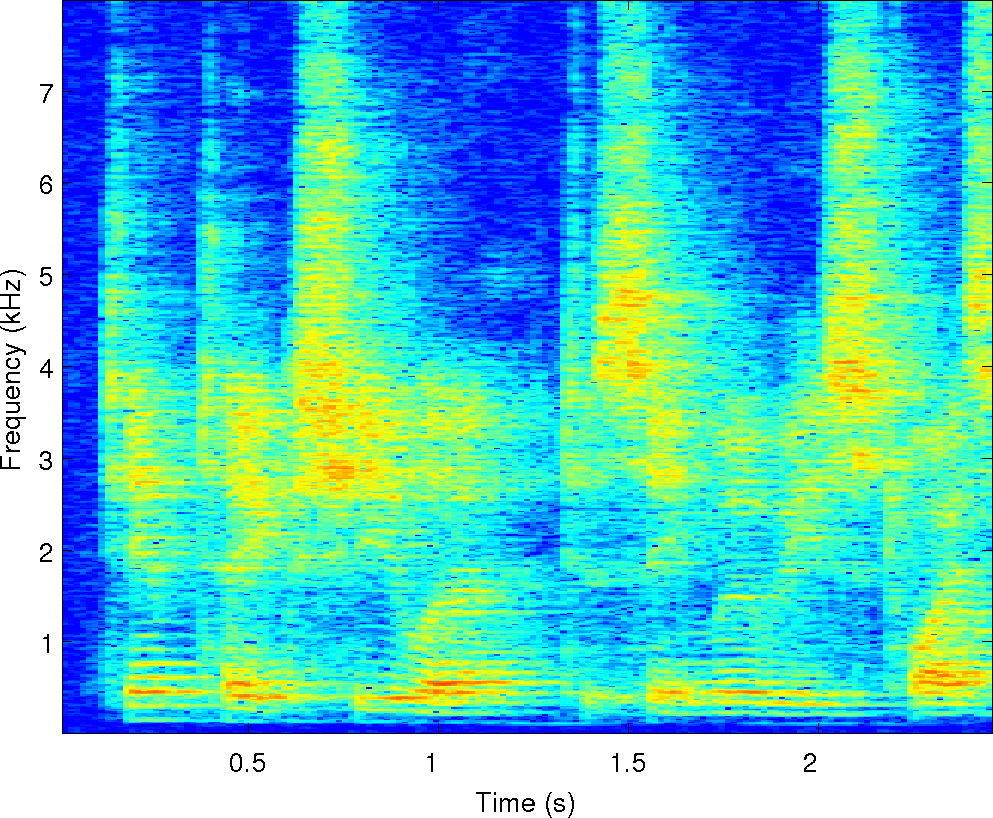
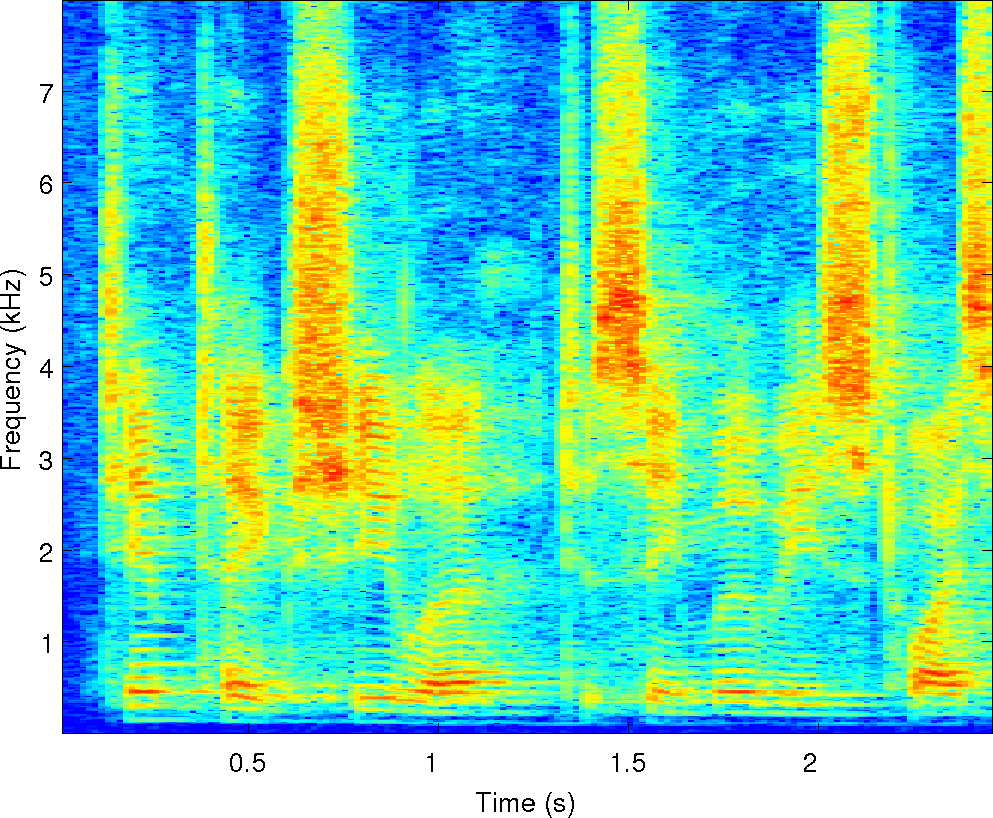
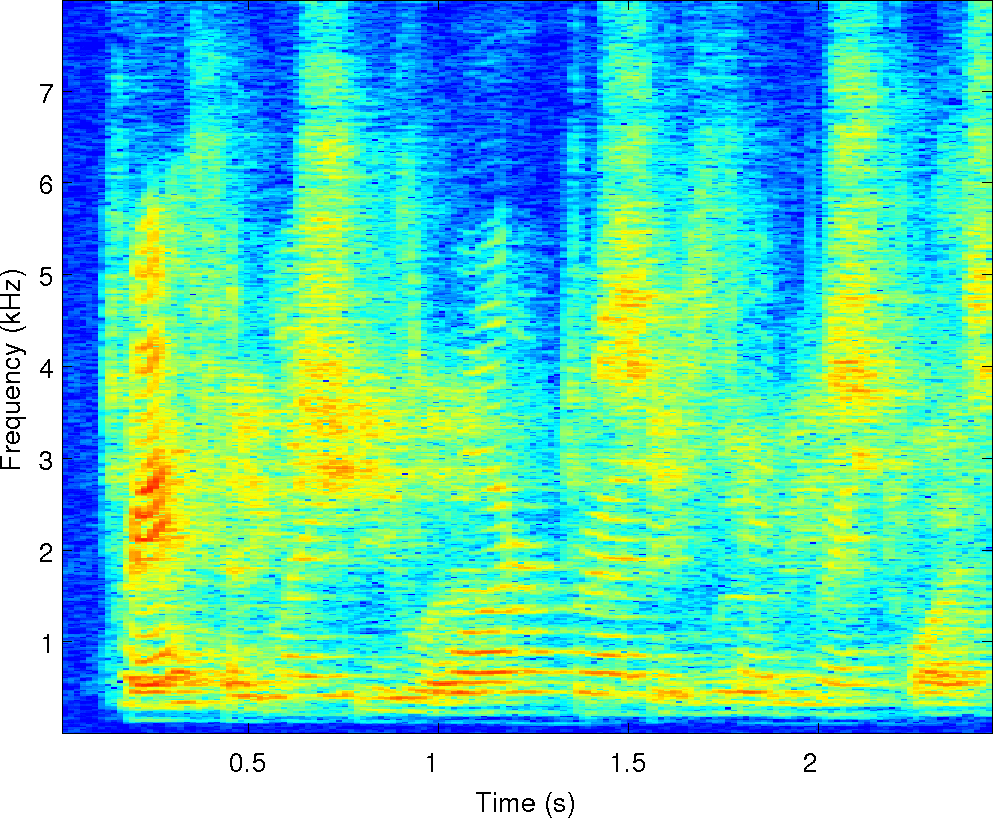
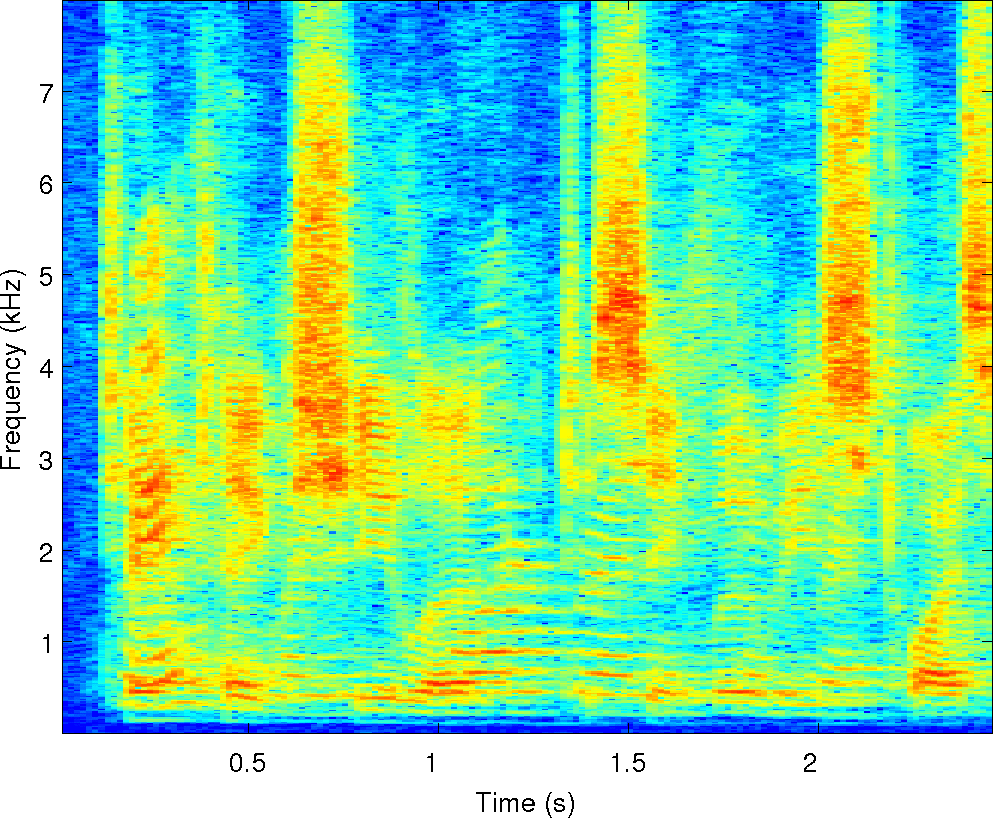
Below is an example of the analysis of a single mixture of two
speakers in reverberation. We've run our two separation algorithms on
it along with the other four algorithms compared in the paper. There
are sound examples and masks from each of them along with spectrograms
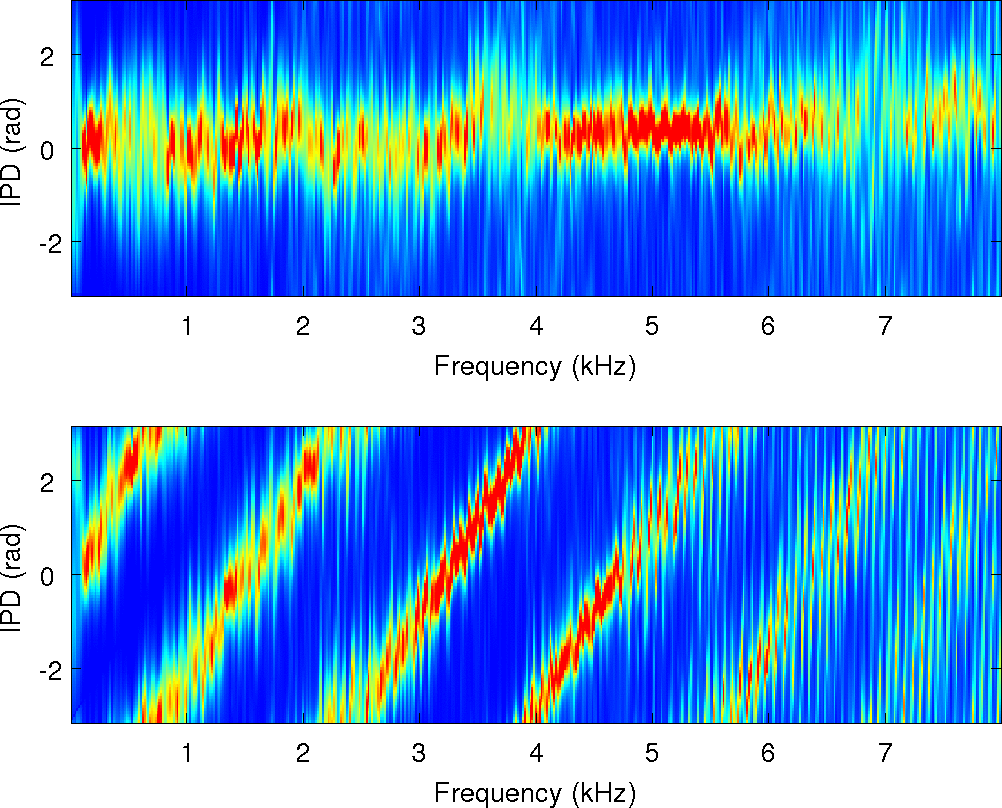
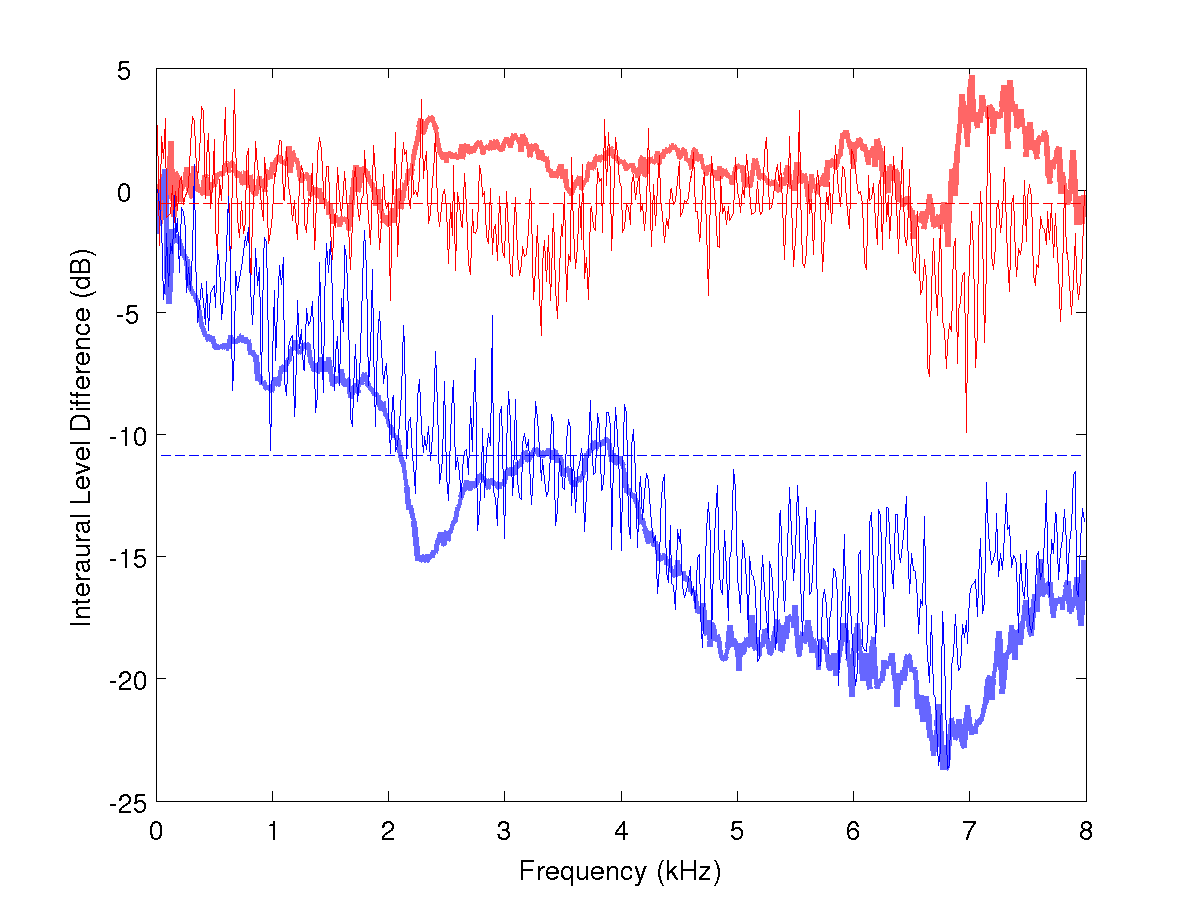
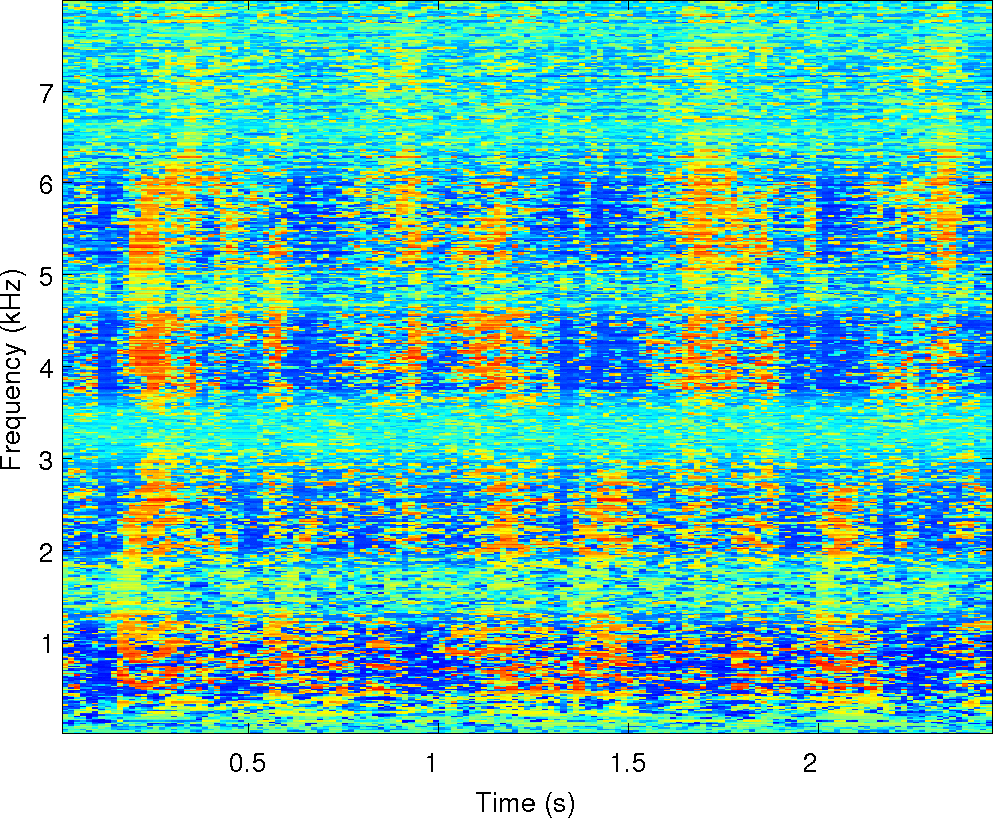
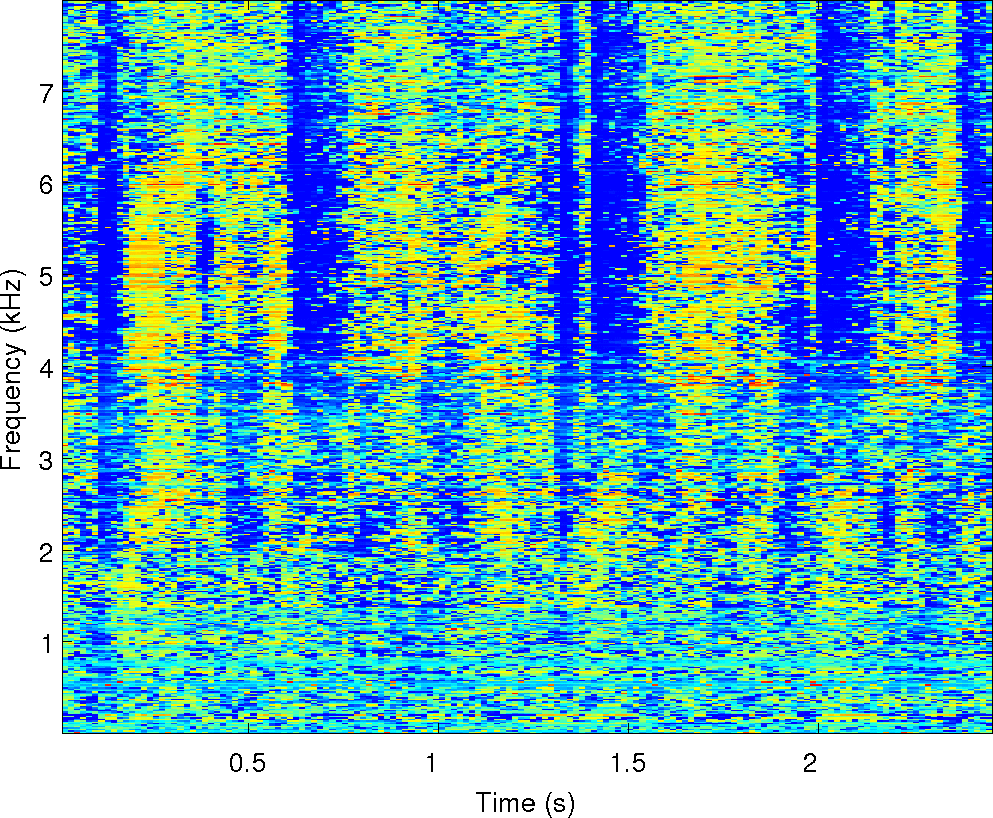
of the observations and the cues that MESSL uses. For each of these
examples, the signal-to-distortion ratio is given in dB for each
algorithm.
In the first
example,
Speaker 1 is a female speaker directly ahead of the listener
saying "Presently, his water brother said
breathlessly."
Speaker 2 is a male speaker located at 75 degrees to the left of
the listener, saying "Tim takes Sheila to see movies twice a
week."
In the second
example,
Speaker 1 is the male speaker from the previous example located
directly ahead of the
listener.
Speaker 2 is a male speaker located at 30 degrees to the left of
the listener, saying "She had your dark suit in greasy wash water all
year."
The speech comes from the
TIMIT dataset and the binaural room impulse responses come from Barbara Shinn-Cunningham's
lab. Please contact Prof. Shinn-Cunningham if you would like to use
them in your own research. The anechoic impulse responses we used in
the paper are from the CIPIC Lab and are available for download from
their
website.
Sound examples
Masks
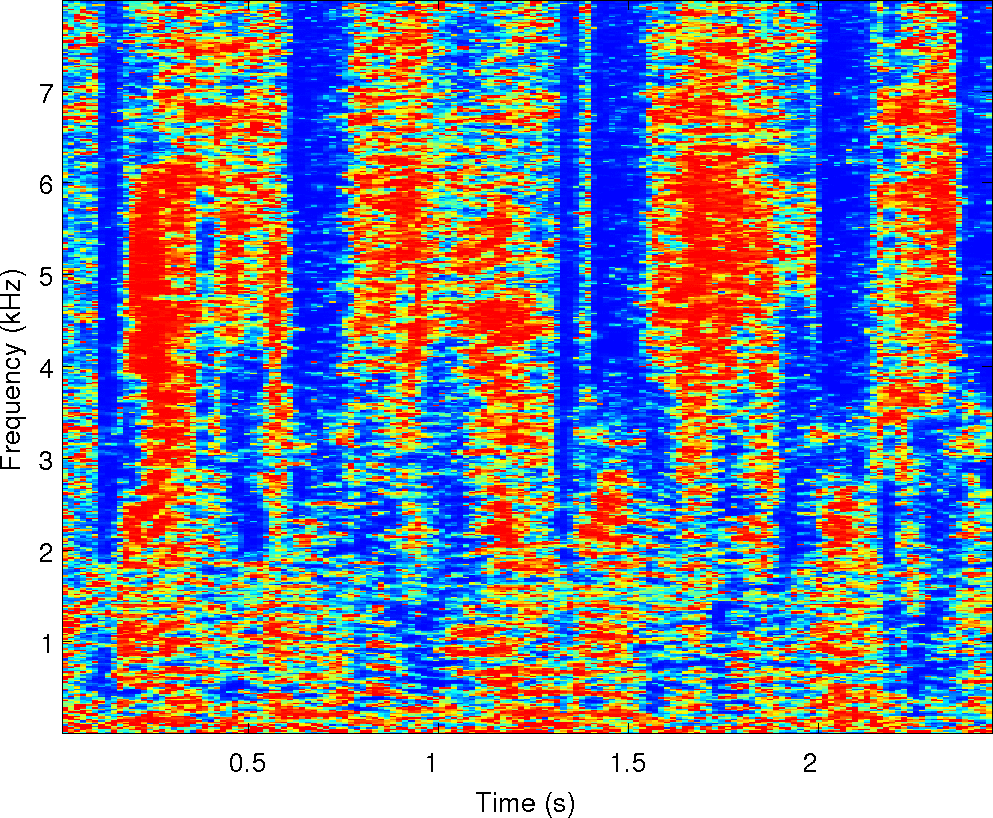
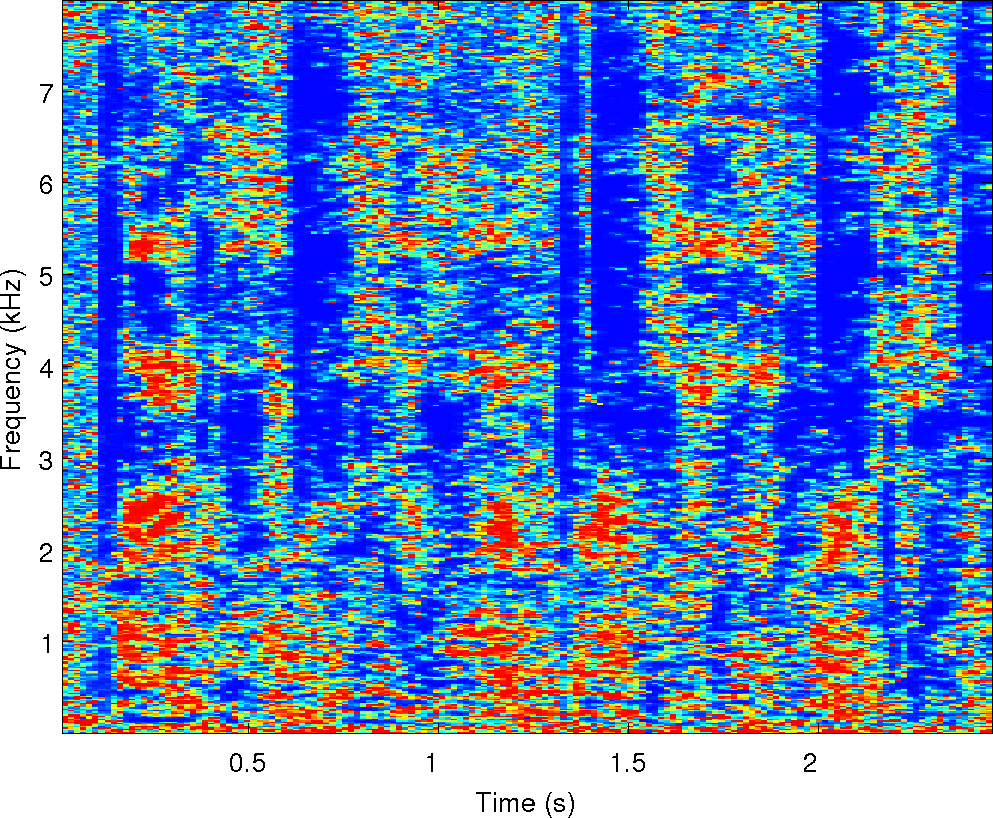
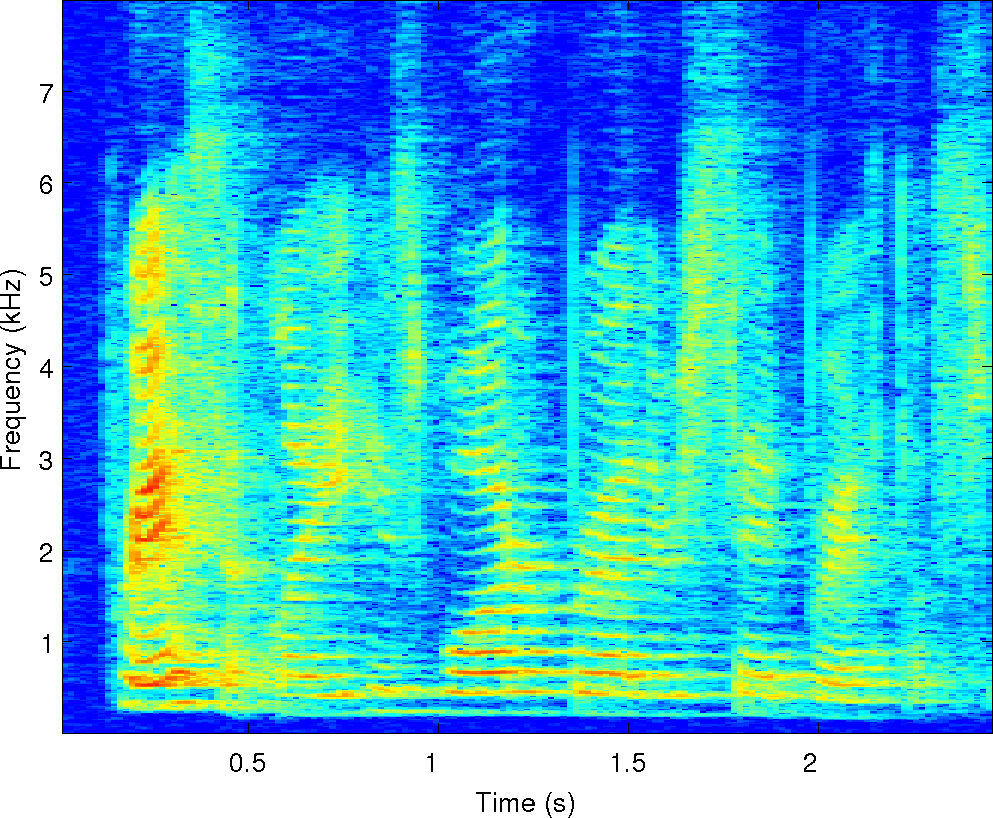
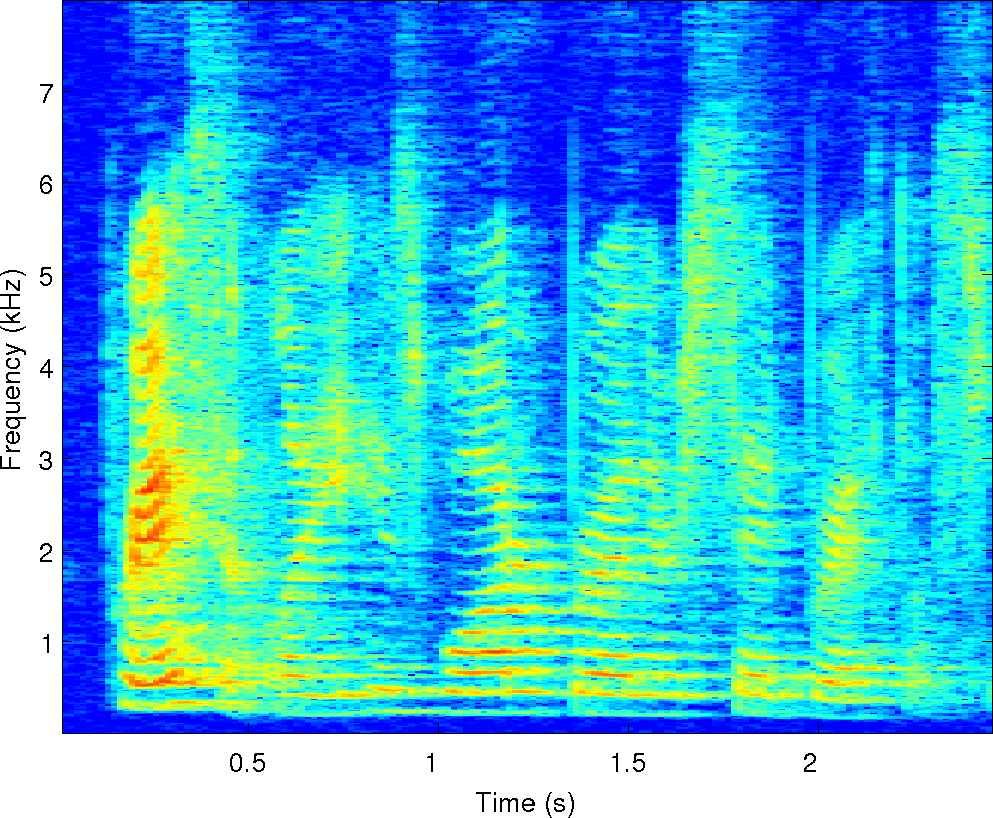
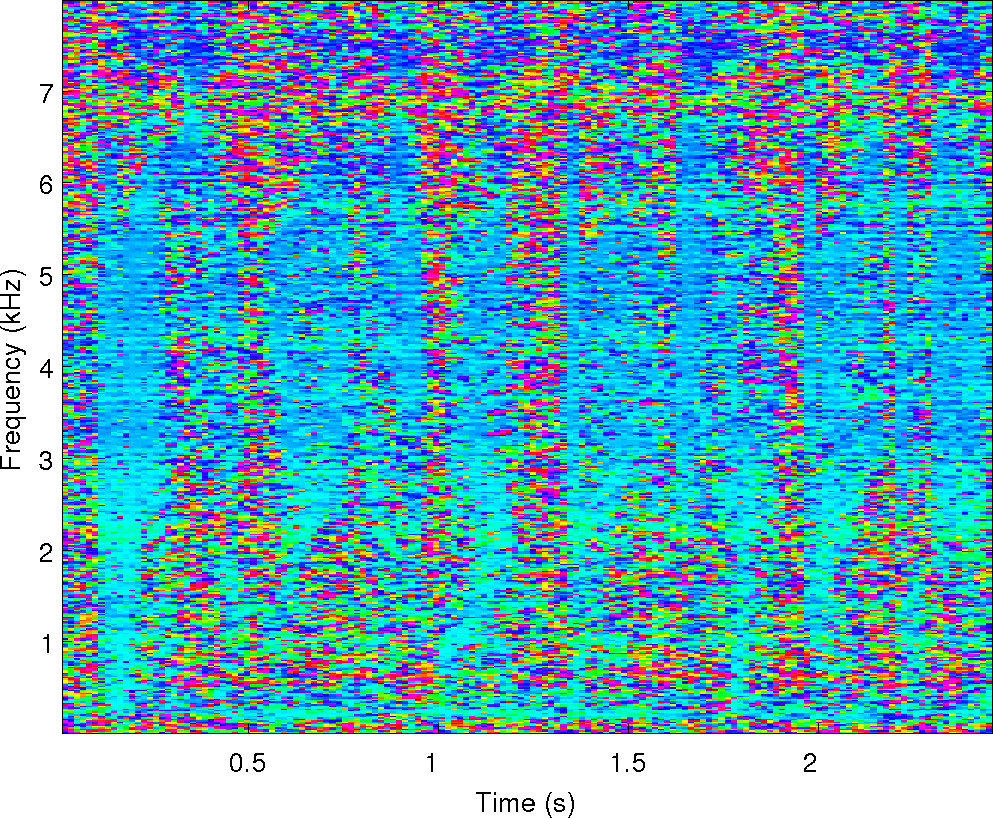
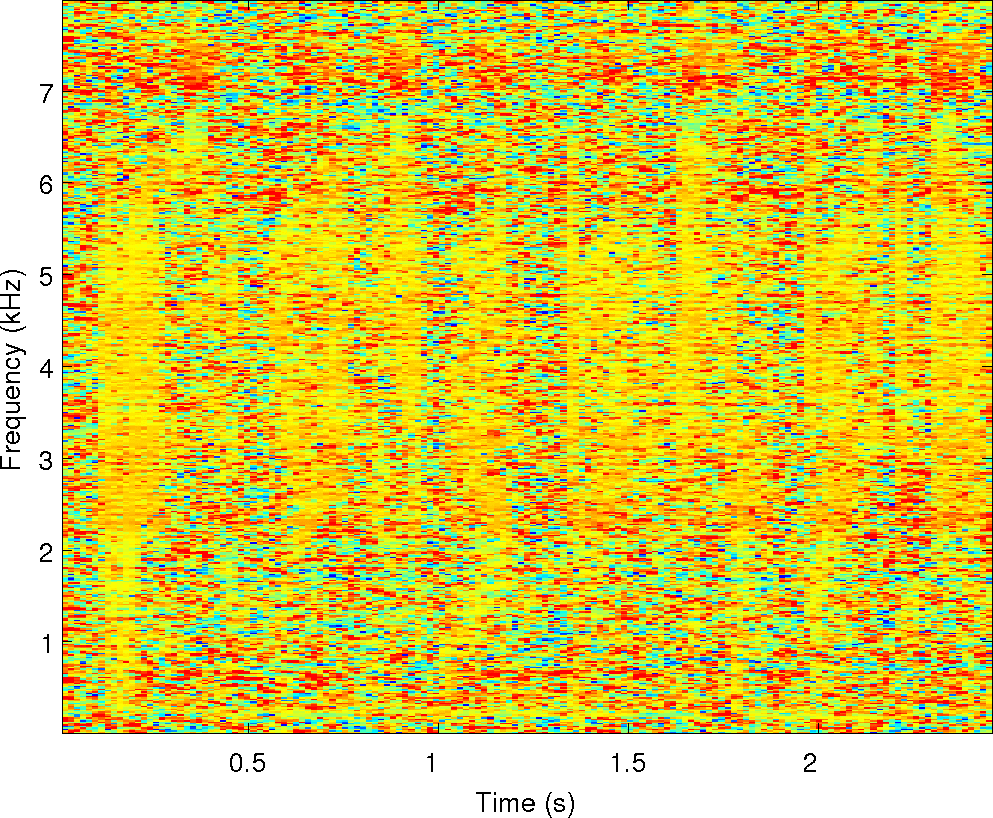
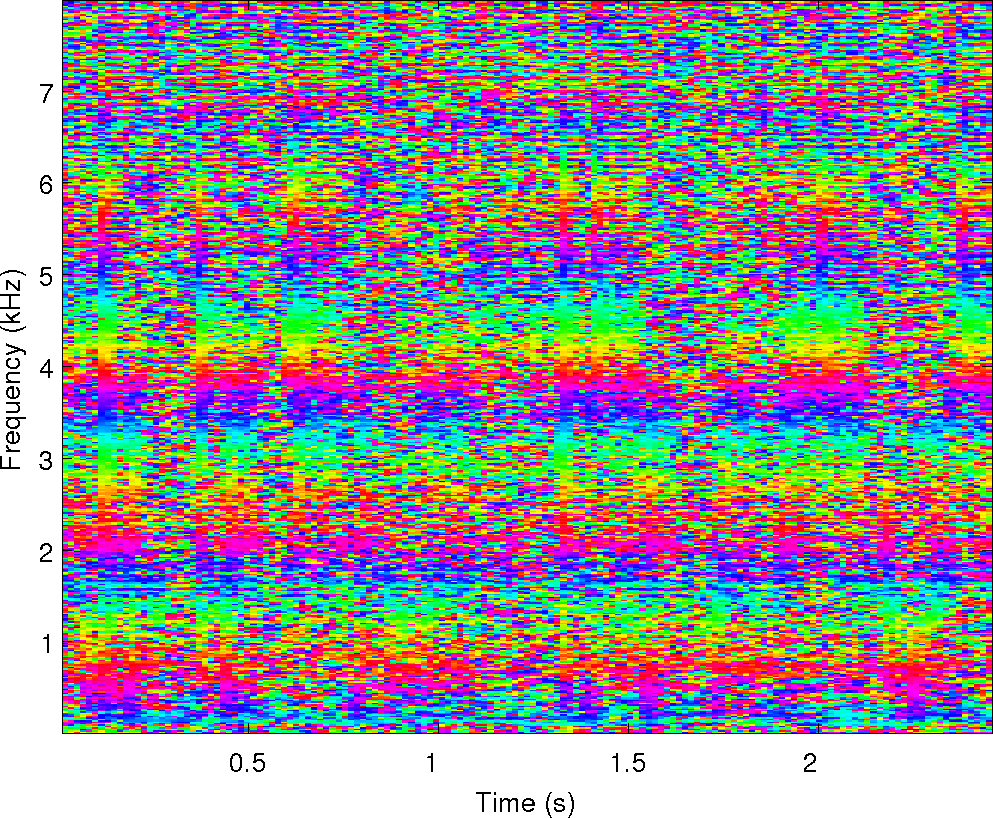
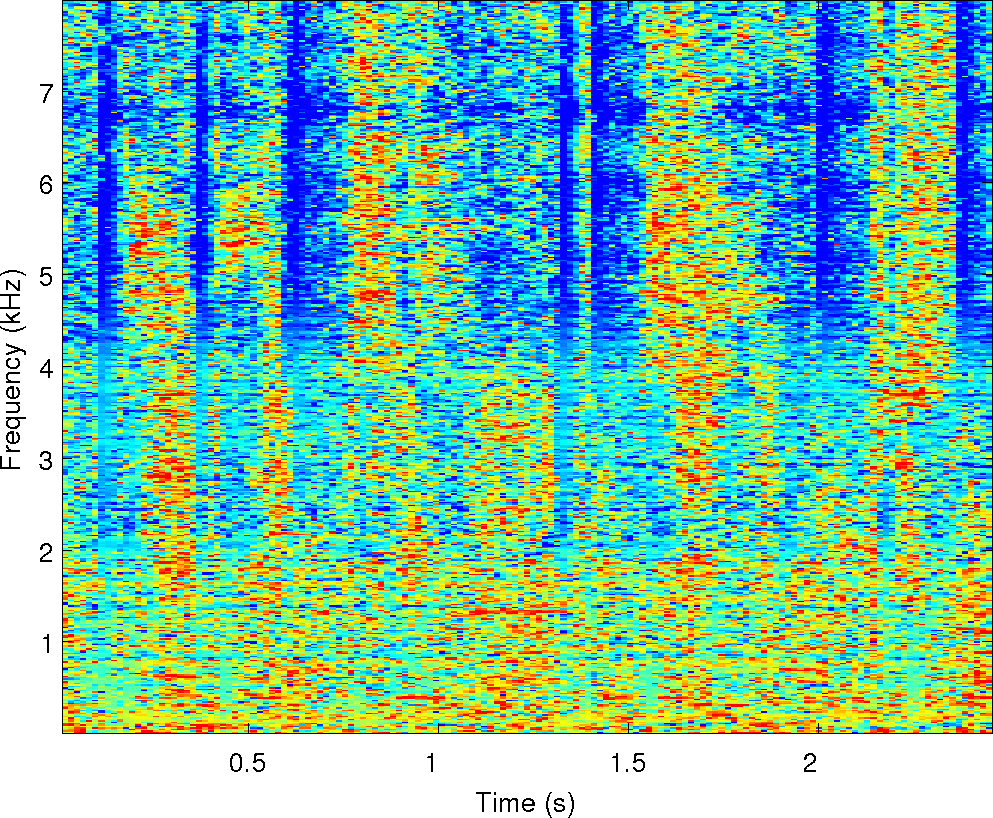
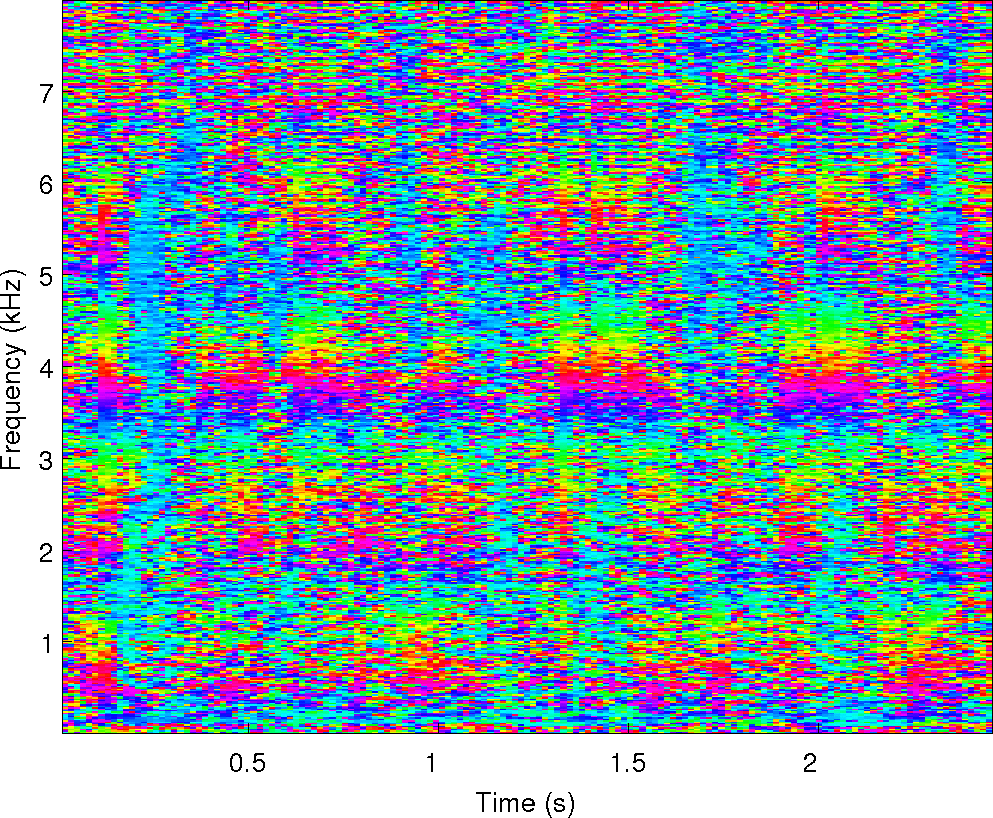
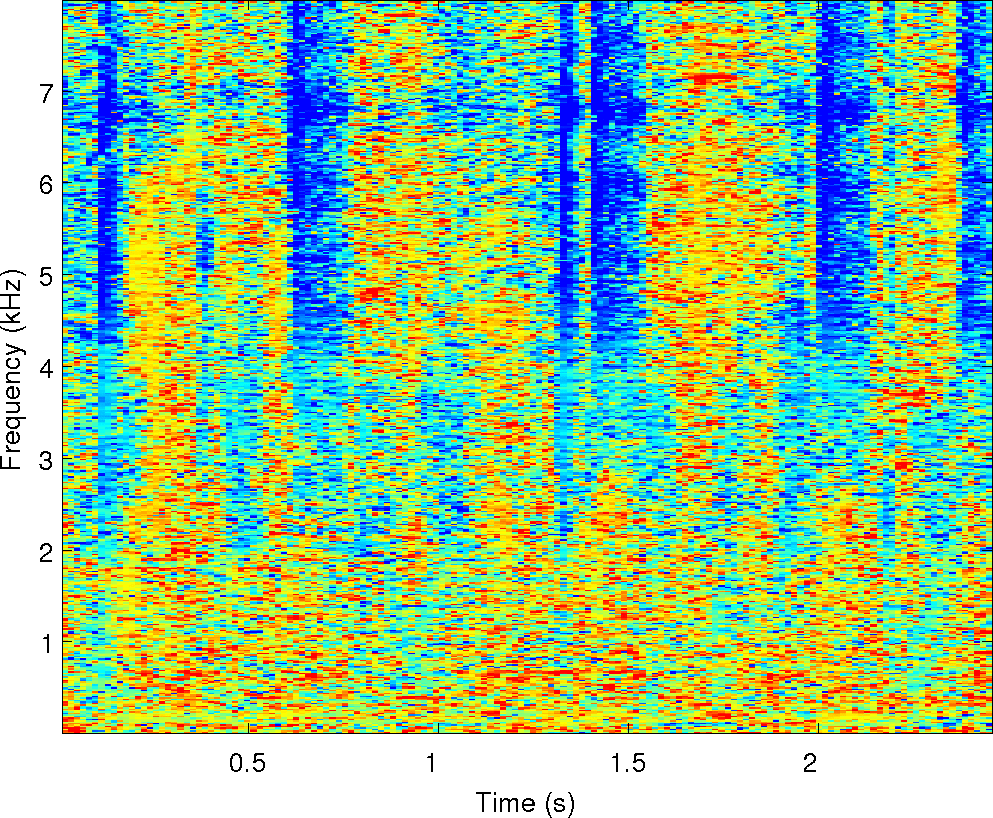
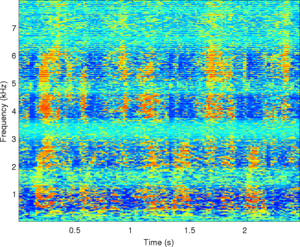
Observations: left and right ears
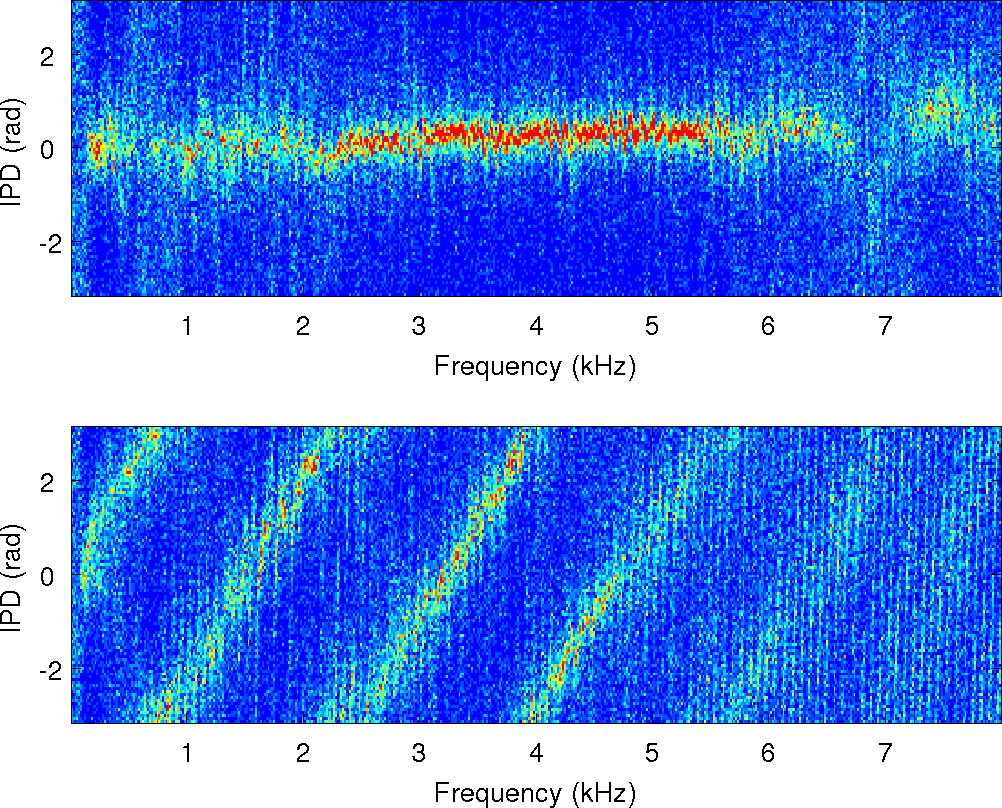
Observations: IPD and ILD
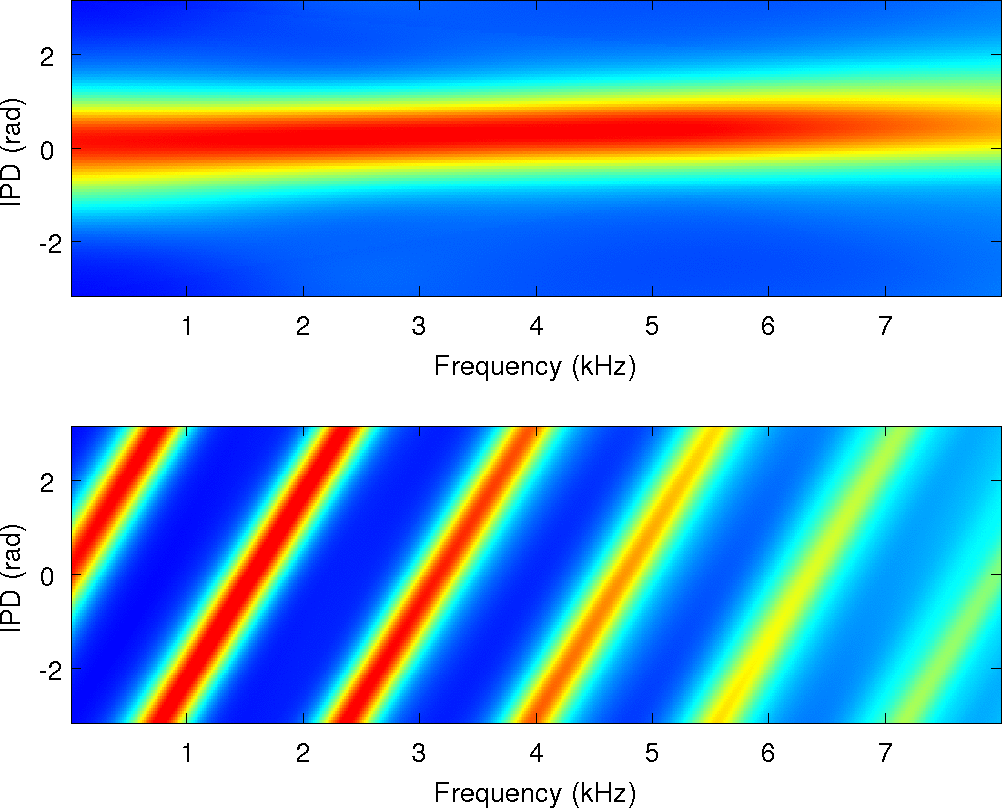
IPD Estimates of MESSL
| Observation histogram |
PDF estimated by MESSL-11 |
PDF estimated by MESSL-WW |
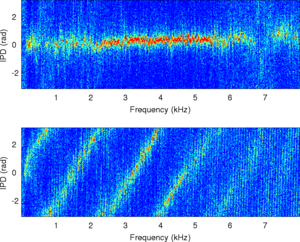 |
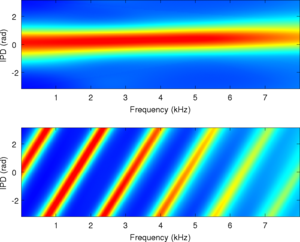 |
 |
ILD Estimates of MESSL
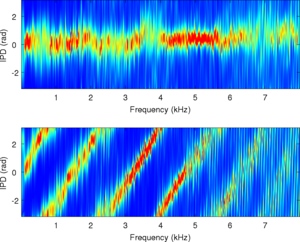
IPD and ILD likelihood contributions for MESSL-WW
| IPD contribution |
ILD contribution |
Combined |
 |
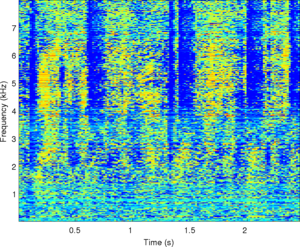 |
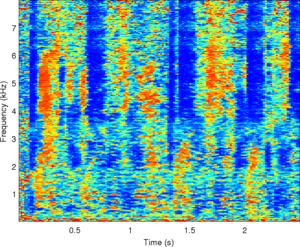 |